环境
- CDH 5.15.2
问题描述
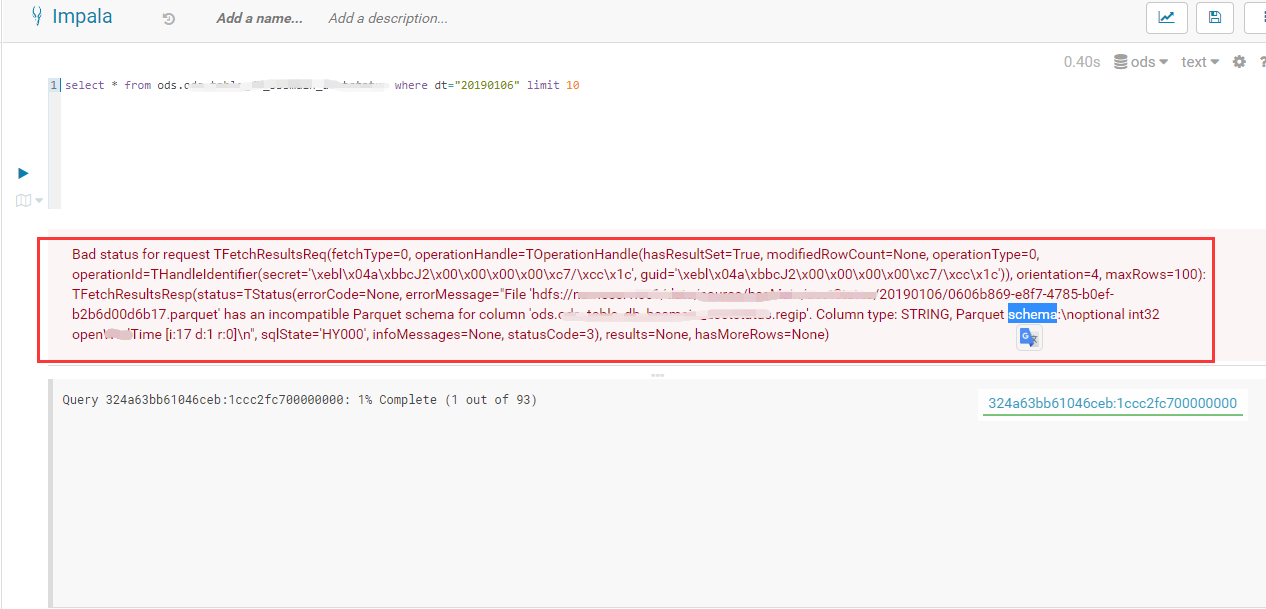
由 Sqoop 从 DB 导入的一张数据表,在 Hive 中能够正常查询。但是将数据导到 Impala 并使用 Impala 进行查询时,若涉及到数据表中的某个列,如 select regip from xxx where xxx , select * from xxx where xxx ,会出现上图的异常。异常的大概意思是 Schema 不兼容,列数据的类型为 STRING, 但数据类型为 int32。
原因
根据异常信息,从Google 检索到导致的原因大概是 Impala 数据表的 Schema 发生变动,与底层的 Parquet 不一致。
在 Parquet 文件中包含元数据存储 Parquet 文件中列的字段名以及对应的类型;而 Hive 也会在 MetaStore 中存储 Hive 数据表的字段名以及类型;而 Impala 会复用 Hive 数据表的 Schema 字段信息。在使用 Hive 进行查询时,Hive 会检查列的名称是否在 Parquet 文件中存在,同时检查列的类型是否匹配,如果名称和类型都匹配那么读取该列的数据。但是 Impala 的查询并非这样。

由上图的文档可知,Impala 获取 Parquet 对应一列的数据默认是基于列的顺序位置。也就是说,Impala 的查询,它会假设数据表中列的顺序与 Parquet 文件中列的顺序一致,在读取列的数据时只会检查类型是否匹配,而忽略列的名称。
经查证,我在导入 DB 数据表的时候没有限定需要的列字段以及顺序,因此导入后Parquet 文件的 Schema 按的是原来 DB 数据表的字段顺序。但是我在创建 Hive 数据表时并没有按照字段在 DB 数据表中的顺序。这就直接导致了,按照列的顺序,某一列在 Parquet Schema 中的类型为 int32,而在 Hive Schema 中的类型为 string,取出数据后发现类型错误。
解决方案
要解决字段类型错误,只需要让 Impala 能够获取到正确的列数据
方案一
重新创建 Hive 数据表的 Schema,使得 Schema 中的字段顺序与底层 Parquet 文件一致。这在数据表字段发生变化的时候可能会引起不必要的麻烦
方案二
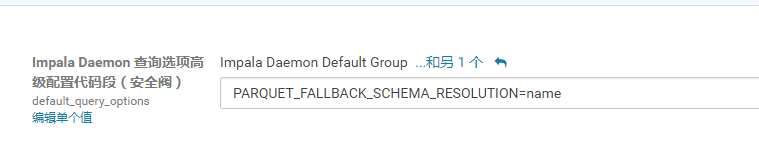
使用 Impala 查询时设置参数
PARQUET_FALLBACK_SCHEMA_RESOLUTION=name来要求 Impala 使用列的名称来解析 Parquet 中对应的列。该配置从CDH 5.8 / Impala 2.6版本开始加入。如果说使用 Impala 查询都是基于列的名称为主,那么可以在全局配置 Impala 的查询参数,这样就无需每次查询都要手动配置参数了。